[VC-04] Subagents from Basic to Deep Dive: I misunderstood!
[Article 04 in the series “Vibe-coding with Claude Code”]

Translated from:


Foreword:
This fourth article was supposed to be about Claude Code’s “Commands,” but recently I discovered quite a few mistakes I made in using Subagents, so I decided to shift the Commands article to number 05. For now, I’ll share the mistakes I’ve encountered 😅
Overview of Claude Code Subagents
(*) CC = Claude Code
How to create a Subagent
Use CC’s /agents command to quickly create one, then open the MD file to customize it to your liking.
# Open sub agents interface
/agents
# Select “Create New Agent”
# Select project-level or user-level
Understand “delegation”
By default: Claude Code (CC) itself is the Main Agent, and will execute everything.
According to Claude’s documentation, after we create subagents, CC will automatically summon the relevant agent and delegate tasks when needed “intelligently” (so intelligently that it rarely summons subagents; the main agent usually handles everything itself, like: “this is easy, I’ll do it!” 😂)
Therefore, to summon subagents more effectively, we have 2 ways:
1/ Automatically (more than the default “intelligent” way):
Add the following instructions to CLAUDE.md to remind CC that it has an army below:
...
During the implementation process, you will delegate tasks to the following subagents based on their expertise and capabilities
- Use `planner-researcher` agent to plan for the implementation plan.
- Use `database-admin` agent to run tests and analyze the summary report.
- Use `tester` agent to run tests and analyze the summary report.
- Use `debugger` agent to collect logs in server or github actions to analyze the summary report.
- Use `code-reviewer` agent to review code.
- Use `docs-manager` agent to update docs in `./docs` directory if any.
...
2/ Manually - Include in prompt or use Command (user prompt):
Next, it’s important to know that there are two forms of subagent summoning: “Chaining” and “Parallel”
Chaining Sub-Agents
# Complex workflow example
> First use the code-analyzer subagent to find performance issues,
> then use the optimizer subagent to fix them
Parallel Execution
# Competing approaches
> Deploy 2 subagents in parallel:
> Subagent 1 - Incremental Modernizer: Design gradual migration strategy
> Subagent 2 - Complete Rewrite Advocate: Propose full stack modernization
(*) Because spawning multiple subagents simultaneously and having them work in parallel can easily cause conflicts, we only use this depending on the workflow and nature of each agent. It is best to configure it into a command to trigger which type of workflow when needed.
Note, each sub-agent has:
Separate context window - not affected by the main conversation
Customizable system prompt - “trained” for a specific role
Separate tool access - only allowed to use necessary tools
Deep expertise - 100% focused on domain expertise
Benefits that subagents can bring:
1. Context Preservation
Instead of having to explain from scratch every time a task changes, each sub-agent maintains its own context. The main conversation remains clean and focused.
2. Specialized Expertise
A sub-agent fine-tuned for security will always be better than a general AI when reviewing security code. The success rate is significantly higher.
3. Reusability & Team Sharing
Create once, use forever. Share with the team for consistent workflow.
4. Parallel Processing
Instead of sequential work: analyze → code → test → review, you can run multiple sub-agents in parallel.
Pro tip: Join the subreddits “r/ClaudeAI” and “r/ClaudeCode” to share and learn sub-agents from the community. This is where experts are experimenting and sharing interesting approaches.
Some other useful repos
List of subagents for reference (refer to the description and workflow to customize your agents, don’t copy them verbatim)
Claude Sub-Agent Spec Workflow System
This also has many clever workflows; I also referenced it to build my subagents.
https://github.com/zhsama/claude-sub-agent/blob/main/README.md
Time to Deep-Dive!
Has anyone else encountered this situation like me: having a team of “god-like” AI agents that can do everything, but when you use them... sometimes they work, sometimes they don’t?
Sometimes they work so wonderfully that they burn tokens at millions of kilometers an hour, but sometimes they give unexpected results, or get stuck in a loop of endless bug fixing?
I found myself in a similar situation a few days ago. I felt that using Subagents wasn’t very effective, only consuming tokens and time... and I was still stuck solving a Test Suite for almost 3 days. So, I decided to dig deeper, and here’s what I learned...
Context Management is key!
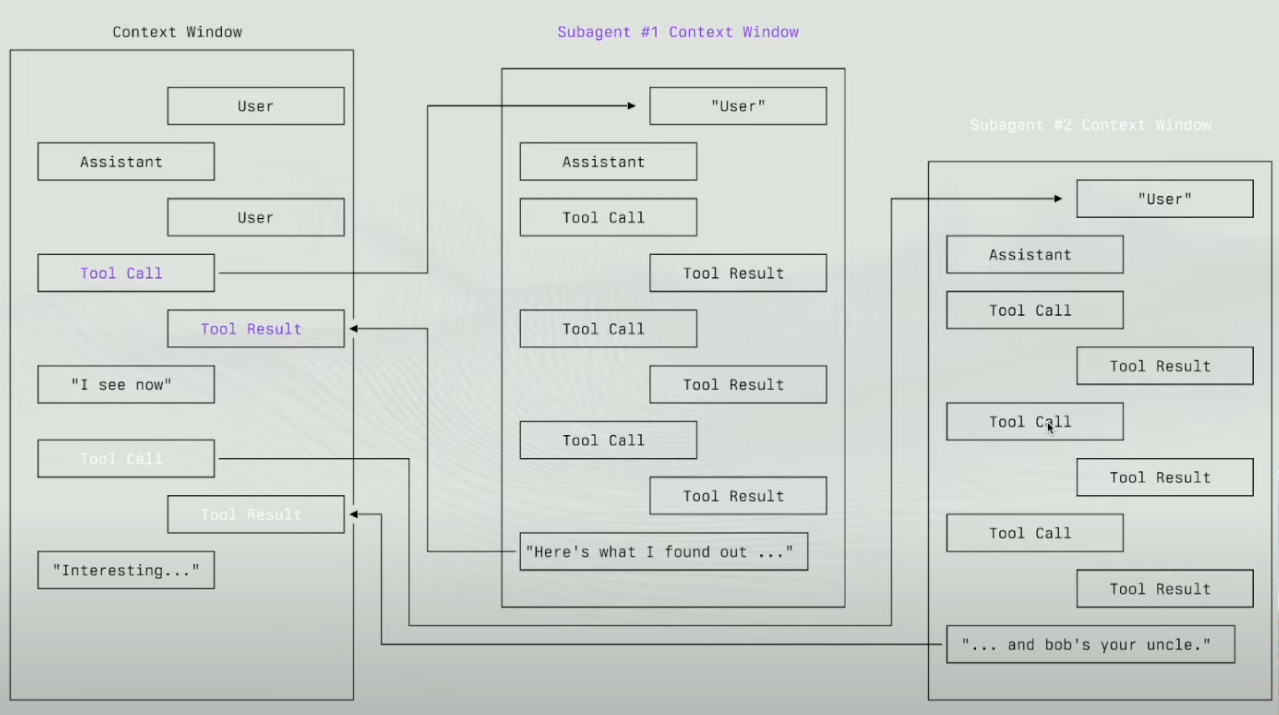
Understand the Context Window of a Multi-agent System
Basically, when I work with an AI agent, the context window contains everything: user messages, AI responses, tool calls, and their results. The problem is that this “box” has a limit.
When CC is active, the Context Window will quickly fill up.
Imagine this:
Input (2k tokens) → Agent Thinking (32k tokens) → Tool Calling & Code (40k tokens) → Output (3k tokens) → User Request (1k tokens) → More Agent Thinking (8k tokens) → More Tool Calling (50k tokens) → Degraded Output (2k tokens)
Total: ~148k tokens! 🔥
Just a few more rounds and the context is exhausted.
Context Management: Using File System as Memory (specifically Markdown files)
The other day I read research by the Manus team on how they manage Context. This article is incredibly good, and I truly respect how the Manus team shares all their secrets to contribute to the AI community. I think you should read it too:
https://manus.im/blog/Context-Engineering-for-AI-Agents-Lessons-from-Building-Manus
Learning from how the Manus team uses the file system to manage context, I immediately applied it to my workflow with Claude Code.
In the system prompt of the “planner-researcher” agent, I added instructions to record the implementation plan and todo tasks in a markdown file in the “./plans” folder, and then attach the file path in the summary report. This way, the main agent and other agents can read this file when needed, without attaching the entire content to the main context window (saving a lot of tokens here).
For example: (refer to the detailed description in my repo)
...
- Break down the implementation into phases and tasks
- Create detailed step-by-step implementation instructions
- Create a comprehensive plan document in `./plans` directory
- Use clear naming as the following format: `YYYYMMDD-feature-name-plan.md`
...
Folder structure:
docs/
product-pdr.md # Product Development Requirements
codebase-summary.md # Summary of code base, structure, code standard,...
api-docs.md # API Documentation
plans/
20250820-authentication-implementation-plan.md
20250821-fix-github-actions-failure.md
...
Context Rot:
Another interesting point was revealed in a study by the Chroma team:
“Context Rot - the phenomenon where LLM performance degrades as input length increases, even for simple tasks.”
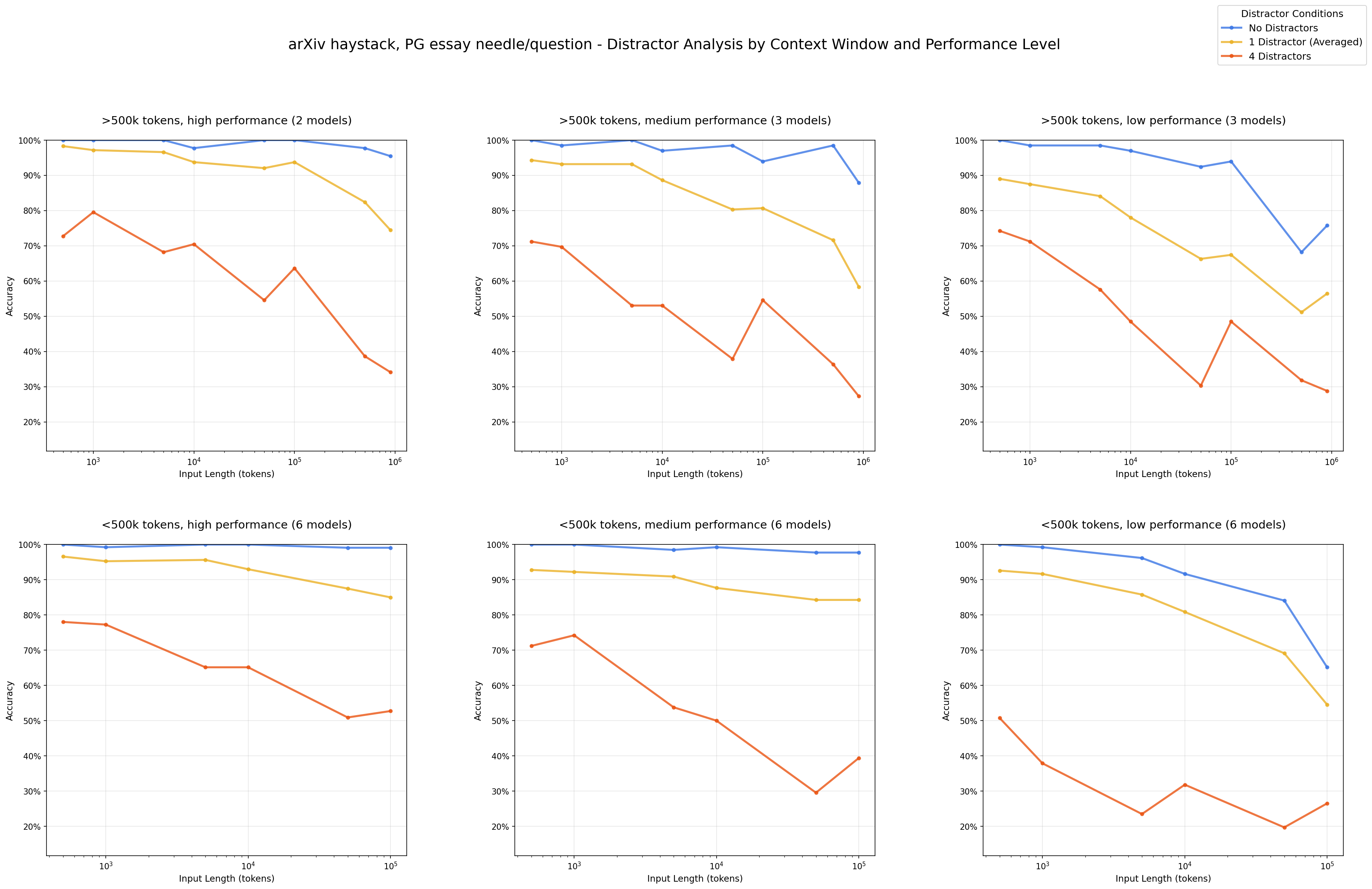
Read more here: https://research.trychroma.com/context-rot
Even a single distractor reduces performance relative to the baseline (needle only), and adding four distractors compounds this degradation further.
This study made some rather shocking discoveries:
1. Needle-Question Similarity
When the semantic similarity between the question and the information to be found decreases, model performance degrades faster with increasing input length.
This is important because in reality, we rarely have questions that perfectly match the available information.
2. Distractors
Even a single distractor reduces performance compared to the baseline. Adding four distractors? Performance “drops like a rock”!
Interestingly, GPT models tend to “hallucinate” (make things up) when confused, while Claude models refuse to answer.
3. Haystack Structure
This is the most counter-intuitive finding: a text with a clear logical structure makes information retrieval more difficult than a randomly scrambled text!
Models seem to get “stuck” in following the flow of thought of the text instead of focusing on finding specific information.
This study clearly shows that increasing the context window is not the ultimate solution to improve AI’s reasoning ability (something I once thought, “why don’t LLM makers just give us a context length as long as the Gemini model?”).
Instead, how information is selected, structured, and presented to the model is the decisive factor.
This is the “Context Engineering” strategy we should aim for:
Prioritize Semantic Proximity: Ensure that questions and relevant information have high semantic similarity.
Minimize Distractors: Eliminate distracting information, especially information that “looks right but is wrong.”
Structure Over Coherence: Sometimes, breaking down information into independent chunks is more effective than maintaining a coherent, logical structure.
Length Optimization: Find the sweet spot between sufficient context and avoiding degradation.
I believe an effective AI system is not one that can “swallow” the most information, but one that knows how to process information correctly.
Okay, let’s continue!
After understanding more about the Context Window, I realized...
I also misunderstood sub-agents!
Initial Problems with Sub Agents
When Claude Code first launched the Sub Agents feature, many people (including myself) encountered situations where:
Slower than the main agent
Token-hungry like water
Results were not better than letting the main agent do everything
This happened because most of us misunderstood the design purpose of Sub Agents.
Why does Claude Code need Sub Agents?
The Claude Code agent works with a variety of tools: reading files, listing files, editing files... The problem is that the read tool can “devour” thousands of tokens because it has to put the entire file content into the conversation history.
Before Sub Agents:
Main agent reads many files → Uses 80% of the context window
Enables “compact conversation” → Summarizes the conversation
Performance degrades sharply due to loss of context
Sub Agents were created to:
Delegate research tasks to a subordinate agent
The subordinate agent works separately, only returning a short summary
The main agent receives condensed information instead of raw data
Common Mistake: Using Sub Agents for Implementation
Many people (including myself at first) thought:
Frontend Dev Agent → Does frontend
Backend Dev Agent → Does backend
Parent Agent → Only orchestrates
The problem: Each Sub Agent only knows about its own task and has no context about the entire project. When a bug needs fixing, they are completely “blind” to what has happened.
Using the right tools for each agent
Another mistake I made (which I think many others might also make) is being too... lazy to configure tools for each agent, allowing every agent to use all tools 😅
Why this is not recommended: Refer back to the context management section above. Allowing all tools enables agents to “overstep their authority” and execute redundant tasks, “polluting” the main context. Additionally, it consumes more tokens (making it easy to hit subscription limits).
Best Practice:
Sub Agents are an army that collects useful information!
(Context Collector Army)
According to feedback from Adam Wolf (a core engineer of the Claude Code team):
“Sub agents work best when they just looking for information and provide a small amount of summary back to main conversation thread”
Here’s how I reorganized my subagent team:
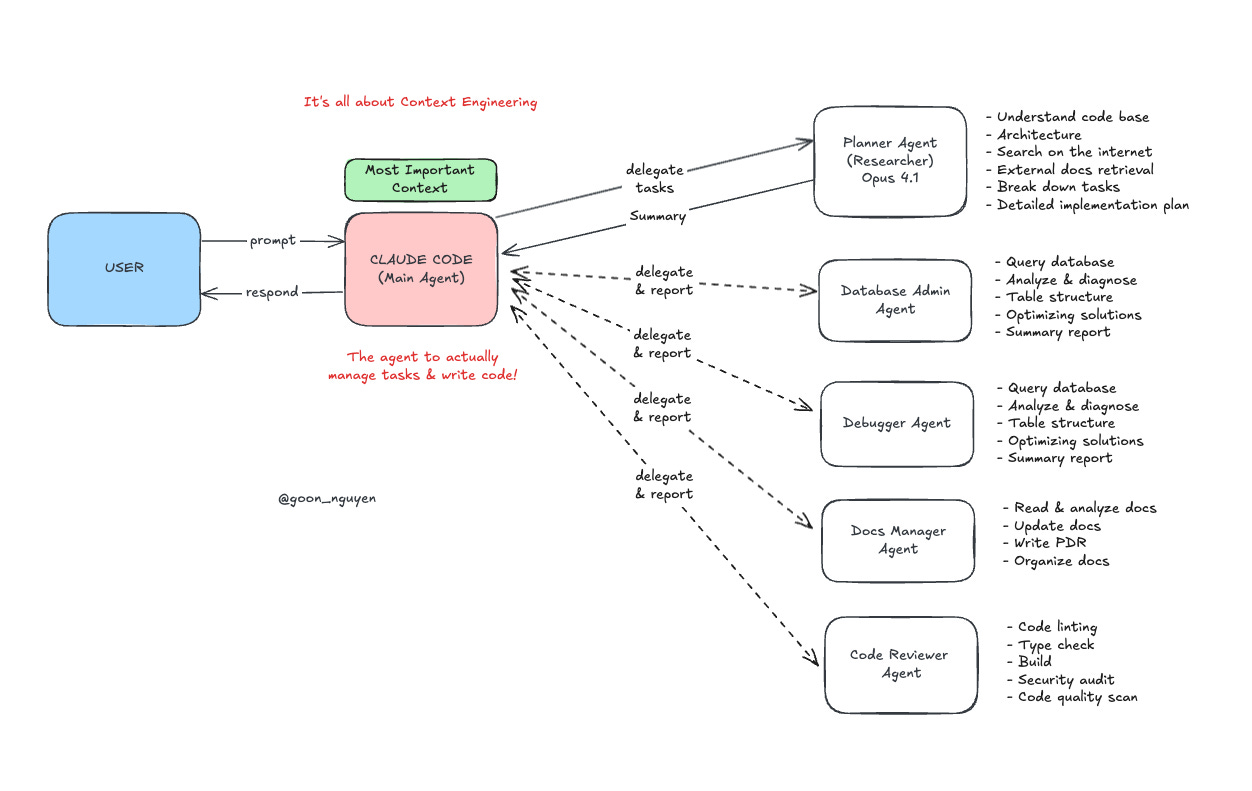
You can find my complete setup here: https://github.com/mrgoonie/claude-code-setup
And here’s a summary of the tasks of each specialized agent:
Planner (Researcher)
Understand code base
Architecture
Search on the internet
External docs retrieval
Break down tasks
Detailed implementation plan (in Markdown file)
Debugger
Analyze CI logs
Query database
Analyze & diagnose
Table structure
Optimizing solutions
Summary report
Tester
Run the whole test suite locally
Run specific tests for quick analysis
Analyze logs
Provide a detailed plan for the fixes
Database Admin
Query database
Analyze & diagnose
Table structure
Optimizing solutions
Summary report
Docs Manager
Implementation standards: Codebase structure, Error handling, Input/Output Validation,...
Read & analyze docs
Analyze codebase & update docs
Write/update PDR
Organize docs
Code Reviewer
Review code quality & best practices
Code linting & Type check
Build to make sure code is compilable
Performance Review
Security audit
As you can see: None of the agents handle the IMPLEMENTATION itself!
All agents now only serve to collect useful information for the Main Context Window of the primary agent (Claude Code).
Then, they feed the plans/reports back to the primary agent (Claude Code itself) to begin execution.
During this implementation process, I always try to follow the following procedure to build up useful context: “Explore - Planning - Execute”
Explore: ensure agents read docs or logs, analyze codebase structure, then summarize key points.
Planning (using Opus): receive reports from the exploration process, analyze them, and develop a detailed implementation plan.
Note: I always make the agent report the implementation plan before starting. I want to make sure its approach is reasonable (don’t trust anyone! hehe).
Execute: after confirming the plan, the main agent will begin executing, then summon subordinate agents to validate upon completion (like
code-reviewerandtester).
Trick: Double Escape - The divine technique
After exploring and building context, Press Double ESC (twice) to fork the conversation. Open a new tab, reactivate Claude Code with the --resume flag. With this method, you can have 5 different Claude Code terminals with the same memory! (the context built up in the previous tab)
Results
I was stuck with the DevPocket API test suite for almost 3 days, and after updating the new agent team, it passed! WOO HOO!
Actually, I could have read the code and fixed this bug faster, but I wanted to truly “vibe code” and see its actual limits.
Key takeaways
Context Management / Context Engineering is critical!
Context Rot: LLM performance degrades as input length increases.
Protect the Main Context at all costs.
Use the File System as Memory to streamline context.
Process for building up useful context: “Explore - Planning - Execute.”
Common Mistake: Using Sub Agents for Implementation.
Sub Agents are an army of useful information collectors! (Context Collector Army)
All of these techniques and workflows are pre-configured and ready to use in ClaudeKit 👇

Conclusion!
BUT (again, every article has a “but” 😂) don’t think it’s the ULTIMATE SOLUTION. There’s no such thing as “one size fits all” in this world.
I’m not saying subagents are the solution to all problems. But it is an interesting approach, with potential, but still needs more experimentation.
Claude Code and the concept of Sub-agents have only been around for 1-2 months. It’s still too new for anyone, and I, like many others, am just trying to experiment and record interesting findings. I have never dared to claim that everything I share is completely TRUE.
(Who knows, in a few days I might find another way to optimize these Subagents! 🫣)
I hope everyone always maintains an A.B.E (Always Be Experimenting) mindset and an “Engineer Mindset” to experiment, record, and contribute to the community so that we can collectively push and challenge the boundaries of AI technology!
That main agent handling everything default really resonated. I've often seen that in my own agentic projecsts.